The NeverLAN CTF challenge JSON parsing 1:
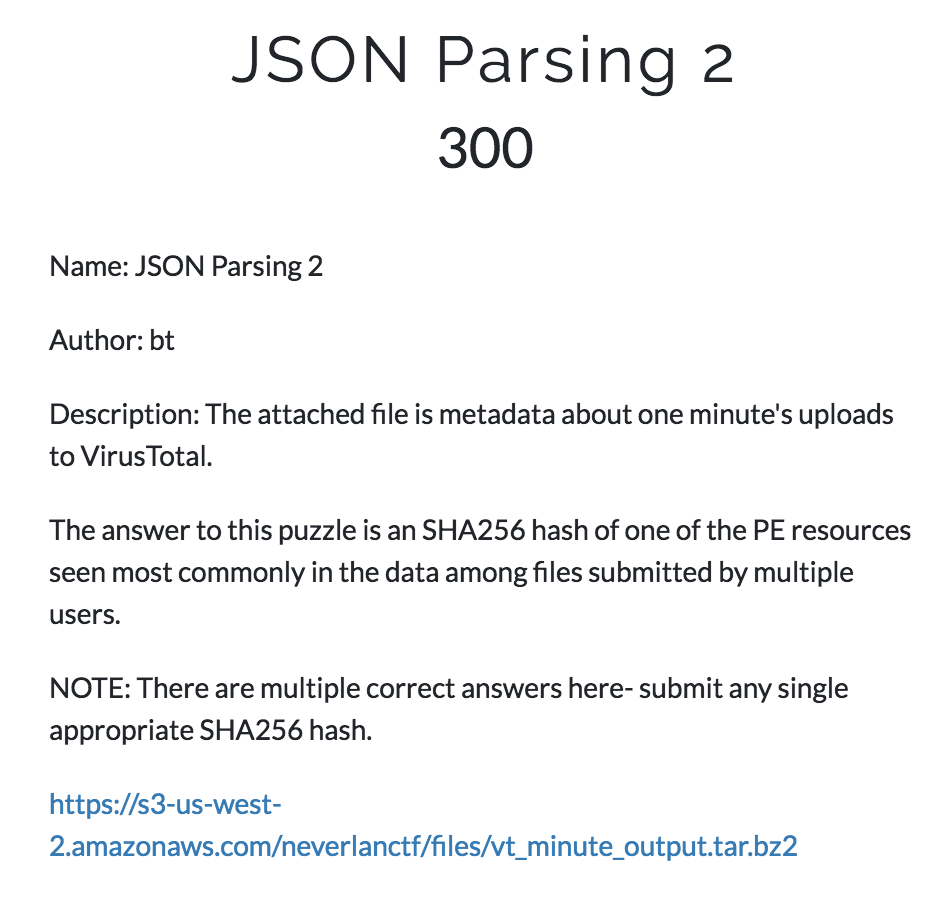
The linked file can be found here.
The JSON file contains a minute of VirusTotal scan logs. The challenge wants us to provide a SHA256 hash of a PE resource which most commonly by multiple users. In the data there is the unique_sources field, this will show us which file was uploaded the most by unique users.
Basically I use a short Python script to format the JSON to be easier read and find the highest number of unique_sources, then search the full file for that record.
from pprint import pprint
import json
with open('file-20171020T1500') as f:
for line in f:
data = json.loads(line)
pprint(data)
Running this script like this:
python json2.py |fgrep 'unique_sources' | cut -d ' ' -f 3|sort -n | tail -1
Will find that there is one record with a unique_sources count of 128.
Searching for like this in the full file:
fgrep 'unique_sources": 128' file-20171020T1500
We get the full scan record back, submitting any of the PE resources SHA256 hashes will work as the flag.

